从石头剪刀布解析 PettingZoo 多智能体环境运行机制以及 Tianshou Experience buffer 存储机制和异步多智能体环境搭建方法
前言
PettingZoo 存在 AEC API 和 Parallel API 两种运行模式。
在 Parallel API 模式的环境中,所有智能体同时进行决策,环境根据所有智能体的动作进行状态转移。如果你将 Parallel API 的示例代码与 Gymnasium 单智能体环境的示例代码进行对比,你会发现两者的代码结构完全一样:
1
2
3
4
5
6
7
8
9
10
11
# PettingZoo Parallel API
from pettingzoo.butterfly import pistonball_v6
parallel_env = pistonball_v6.parallel_env(render_mode="human")
observations, infos = parallel_env.reset(seed=42)
while parallel_env.agents:
# this is where you would insert your policy
actions = {agent: parallel_env.action_space(agent).sample() for agent in parallel_env.agents}
observations, rewards, terminations, truncations, infos = parallel_env.step(actions)
parallel_env.close()
1
2
3
4
5
6
7
8
9
10
11
12
13
# Gymnasium
import gymnasium as gym
env = gym.make("LunarLander-v3", render_mode="human")
observation, info = env.reset()
episode_over = False
while not episode_over:
# agent policy that uses the observation and info
action = env.action_space.sample()
observation, reward, terminated, truncated, info = env.step(action)
episode_over = terminated or truncated
env.close()
两者都是通过 reset 方法初始化环境并且获得初始 observation 。然后在循环内部,智能体先进行决策产生 action ,然后调用 step 方法完成环境状态转移,得到本次 action 的 reward 以及下一次观测 observation 、terminate 和 truncate 。两者唯一的区别在于:Gymnasium 单智能体产生 action 的位置变成了 Parallel API 所有智能体同时产生 action 。
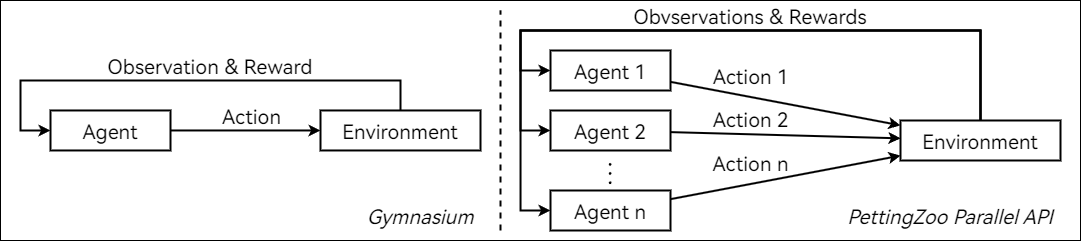
通过与 Gymnasium 对比,理解 PettingZoo Parallel API 的运行机制应该会更加容易。具体如何编写 PettingZoo Parallel API 环境请参照这个教程和这个代码。
但是如果你想用多智能体解决更加复杂的问题,就很有可能需要设计一个更加复杂的多智能体环境,比如:
- 智能体在环境中需要依次决策,而不是同时决策
- 下一个智能体需要根据上一个智能体的决策导致的环境变化进行决策
- 上一个智能体的决策结果需要传递给下一个智能体
- 上一个智能体的决策会决定下一个进行决策的智能体是谁
- 等等一系列奇思妙想……
此时 Parallel API 的局限性不言而喻。
在接下来的部分,我们首先分析基于 AEC API 的石头剪刀布环境代码,分析其运行机制。然后使用 Tianshou 的多智能体强化学习框架与石头剪刀布 AEC API 环境进行交互,解析其 Experience buffer 存储机制。最后,通过魔改 AEC API 石头剪刀布环境,探究异步多智能体环境搭建方法。
PettingZoo AEC API 石头剪刀布环境运行机制
与使用 AEC API 的环境交互的示例代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from pettingzoo.classic import rps_v2
env = rps_v2.env(render_mode="human")
env.reset(seed=42)
for agent in env.agent_iter():
observation, reward, termination, truncation, info = env.last()
if termination or truncation:
action = None
else:
# this is where you would insert your policy
action = env.action_space(agent).sample()
env.step(action)
env.close()
从中可以看出,AEC 环境使用 reset 初始化后不会返回初始 observation ,而是在循环内部使用 last 方法获取当前观测 observation 、termination 和 truncation 以及上一次 action 的 reward 。智能体决策产生 action 后调用 step 方法完成环境状态转移,与 reset 一样没有任何返回值。
在后面的小节中我们将分析 PettingZoo AEC API 剪刀石头布环境的代码,研究其选择 agent 以及生成对应 agent 的 observation 和 reward 的机制。
函数分析
__init__
__init__ 函数定义了环境中不变的固有参数:
self.possible_agents定义了在环境中可能出现的全部 agentself.agent_name_mapping给所有 agent 定义了索引self.action_spaces和self.observation_spaces定义了全部智能体的动作空间和观测空间self.render_mode定义了环境的渲染模式
observation_space 和 action_space
根据 AEC 源码 L113 和 L125 ,observation_space 和 action_space 方法应当根据传入的 agent 参数返回对应的观测空间和动作空间。通常从 self.observation_spaces 和 self.action_spaces 字典中获取。
render
render 方法用于渲染环境。在 human 模式下,会打印当前环境状态。
observe
observe 返回传入 agent 的观测,从储存了所有智能体的观测的字典 self.observations 中获取。
reset
reset 方法用于初始化所有动态变化的环境参数(与 __init__ 中定义的参数不同)。其中包括:
self.agents定义了当前参与决策的智能体(是self.possible_agents的子集)self.rewards为最后一个智能体执行完动作后,环境所产生的所有智能体的奖励self._cumulative_rewards为每个智能体的累积奖励self.terminations、self.truncations和self.infos用于记录所有智能体的状态self.state用于记录当前环境的全局状态self.observations用于记录所有智能体的观测self.num_moves用于记录当前环境的步数self._agent_selector是一个用self.agents初始化的迭代器,用于选择下一个智能体self.agent_selection记录了下一次调用step方法的智能体
step
step 方法是环境根据智能体动作进行状态转移的核心函数。其执行逻辑如下:
- 检查
self.agent_selection的状态是否为terminated或truncated,如果是,则执行self._was_dead_step方法处理这些已经结束的智能体。通过查看源码了解该方法具体完成了什么操作。 - 清空该智能体的累计奖励
self._cumulative_rewards[self.agent_selection]以便在后面的代码中重新计算(提示:last方法返回的奖励来自于self._cumulative_rewards)。 - 使用该智能体的动作更新全局状态
self.state - 接下来的代码执行与当前智能体有关
- 如果当前智能体是第一个智能体,说明还需要等待第二个智能体做出动作,才能知道本轮猜拳的奖励
- 所以更新全局状态
self.state标记第二个智能体尚未做出动作 - 调用
self._clear_rewards清空上一轮猜拳的奖励
- 所以更新全局状态
- 如果当前智能体是第二个智能体,那么就可以计算本轮猜拳的奖励了
- 设置奖励
self.rewards - 更新环境状态
self.num_moves - 更新智能体状态
self.truncations - 更新智能体观测
self.observations
- 设置奖励
- 如果当前智能体是第一个智能体,说明还需要等待第二个智能体做出动作,才能知道本轮猜拳的奖励
- 处理完当前智能体的动作后,设置
self.agent_selection为下一个智能体 - 调用
self._accumulate_rewards方法更新智能体的累计奖励,以供last方法返回 - 调用
self.render方法渲染环境
小结
从 step 函数的逻辑中可以看出,AEC 环境的运行机制是:所有参与决策的智能体按照 agent selector 迭代器的顺序依次决策。每个智能体执行动作后,环境都会发生变化,并且产生一个针对所有智能体的奖励 self.rewards 。这些奖励都会积累在 self._cumulative_rewards 中。当所有参与决策的智能体都执行完动作后,环境会将累计奖励分发给对应的智能体。在下一轮决策开始时,累计奖励 self._cumulative_rewards 需要清零重新计算。

Tianshou Experience buffer 在 PettingZoo AEC 环境的存储机制
从上面对 AEC 环境代码的分析中可以看出:智能体做出决策和获取奖励并不是同步的(即:智能体做出决策后,环境无法立刻返回奖励),必须等到所有智能体动作全部执行完毕后,环境才会返回奖励。
那么 Tianshou 的多智能体强化学习框架是如何处理这种情况的呢?下面将使用 Tianshou 的多智能体强化学习框架与 PettingZoo AEC API 石头剪刀布环境进行交互,通过单步调试观察多智能体与环境交互时 Experience buffer 的变化,来解析 Tianshou Experience buffer 在 PettingZoo AEC 环境的存储机制。
测试代码
将石头剪刀布 AEC 环境代码保存为 aec_rps.py ,并在同级目录下创建 main.py 文件,在其中编写代码实现两个 DQN policy 进行石头剪刀布游戏。代码参考这个和这个,省略了测试 test 相关的代码。
笔者认为
aec_rps.py中的observe方法应当返回一个 OneHot 向量,以适配神经网络的输入,而非一个标量。因此暂时做出如下修改:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
import argparse
from copy import deepcopy
from functools import partial
import gymnasium
import numpy as np
import torch
from tianshou.data import Collector, VectorReplayBuffer
from tianshou.env import DummyVectorEnv
from tianshou.env.pettingzoo_env import PettingZooEnv
from tianshou.policy import BasePolicy, DQNPolicy, MultiAgentPolicyManager
from tianshou.trainer import OffpolicyTrainer
from tianshou.utils.net.common import Net
import aec_rps
def get_env(render_mode: str | None = None) -> PettingZooEnv:
return PettingZooEnv(aec_rps.env(render_mode=render_mode))
def get_args() -> argparse.Namespace:
parser = argparse.ArgumentParser()
parser.add_argument("--device", type=str, default="cuda" if torch.cuda.is_available() else "cpu")
parser.add_argument("--seed", type=int, default=0)
# Parameters for DRL
parser.add_argument("--hidden-sizes", type=int, nargs="*", default=[128, 128], help="Hidden layer sizes of DQN.")
parser.add_argument("--learning-rate", type=float, default=0.001)
parser.add_argument("--gamma", type=float, default=0.99, help="Discount factor.")
parser.add_argument("--td-step", type=int, default=3, help="Number of steps for multi-step TD learning.")
parser.add_argument("--target-update-freq", type=int, default=320, help="Frequency of target network update.")
parser.add_argument("--buffer-size", type=int, default=6, help="Size of replay buffer.")
parser.add_argument("--epsilon-train", type=float, default=1.0, help="Epsilon for training.")
parser.add_argument("--epsilon-test", type=float, default=0.05, help="Epsilon for testing.")
parser.add_argument("--batch-size", type=int, default=64)
# Parameters for training
parser.add_argument("--render-mode", type=str, default=None)
parser.add_argument("--train-env-num", type=int, default=1, help="Number of environments for parallel training.")
parser.add_argument("--test-env-num", type=int, default=1, help="Number of environments for testing the policy.")
parser.add_argument("--epoch-num", type=int, default=10, help="Number of epochs for training.")
parser.add_argument("--step-per-epoch", type=int, default=100, help="Number of transitions collected per epoch.")
parser.add_argument(
"--step-per-collect",
type=int,
default=1,
help="Number of transitions the collector would collect before the network update",
)
parser.add_argument(
"--update-per-step",
type=float,
default=1.0,
help="How many gradient steps to perform per step in the environment.\n1.0 means perform one gradient step per environment step.\n0.1 means perform one gradient step per 10 environment steps.",
)
parser.add_argument("--episode-per-test", type=int, default=1, help="Number of episodes for one policy evaluation.")
if len(parser.parse_known_args()[1]) > 0:
print("Unknown arguments: ", parser.parse_known_args()[1])
return parser.parse_known_args()[0]
def get_env_info(args: argparse.Namespace) -> argparse.Namespace:
env = get_env()
args.state_space = (
env.observation_space["observation"]
if isinstance(env.observation_space, gymnasium.spaces.Dict)
else env.observation_space
) # `env.observation_space` may has `action_mask` key
args.state_shape = args.state_space.shape or int(args.state_space.n)
args.action_space = env.action_space
args.action_shape = args.action_space.shape or int(args.action_space.n)
return args
def get_policy(
args: argparse.Namespace,
policy_self: BasePolicy | None = None,
policy_opponent: BasePolicy | None = None,
optimizer: torch.optim.Optimizer | None = None,
):
if policy_self is None:
net = Net(
state_shape=args.state_shape,
action_shape=args.action_shape,
hidden_sizes=args.hidden_sizes,
device=args.device,
).to(args.device)
if optimizer is None:
optimizer = torch.optim.Adam(net.parameters(), lr=args.learning_rate)
policy_self = DQNPolicy(
model=net,
optim=optimizer,
action_space=args.action_space,
discount_factor=args.gamma,
estimation_step=args.td_step,
target_update_freq=args.target_update_freq,
)
if policy_opponent is None:
policy_opponent = deepcopy(policy_self)
env = get_env()
ma_policy = MultiAgentPolicyManager(policies=[policy_self, policy_opponent], env=env)
return ma_policy, env.agents
def train(
args: argparse.Namespace,
policy_self: BasePolicy | None = None,
policy_opponent: BasePolicy | None = None,
optimizer: torch.optim.Optimizer | None = None,
):
train_envs = DummyVectorEnv([partial(get_env, render_mode=args.render_mode) for _ in range(args.train_env_num)])
test_envs = DummyVectorEnv([partial(get_env, render_mode=args.render_mode) for _ in range(args.test_env_num)])
# seed
np.random.seed(args.seed)
torch.manual_seed(args.seed)
train_envs.seed(args.seed)
test_envs.seed(args.seed)
# policy
ma_policy, agents = get_policy(args, policy_self=policy_self, policy_opponent=policy_opponent, optimizer=optimizer)
# replay buffer
buffer = VectorReplayBuffer(args.buffer_size, args.train_env_num)
# collector
train_collector = Collector(ma_policy, train_envs, buffer, exploration_noise=True)
test_collector = Collector(ma_policy, test_envs, exploration_noise=True)
# train
def train_fn(num_epoch: int, step_idx: int) -> None:
[agent.set_eps(args.epsilon_train) for agent in ma_policy.policies.values()]
def test_fn(num_epoch: int, step_idx: int) -> None:
[agent.set_eps(args.epsilon_test) for agent in ma_policy.policies.values()]
def stop_fn(mean_rewards: float) -> bool:
return False
def save_best_fn(policy: BasePolicy) -> None:
pass
def reward_metric(rewards: np.ndarray) -> np.ndarray:
return rewards[:, 0]
result = OffpolicyTrainer(
policy=ma_policy,
max_epoch=args.epoch_num,
batch_size=args.batch_size,
train_collector=train_collector,
test_collector=test_collector,
step_per_epoch=args.step_per_epoch,
episode_per_test=args.episode_per_test,
update_per_step=args.update_per_step,
step_per_collect=args.step_per_collect,
train_fn=train_fn,
test_fn=test_fn,
stop_fn=stop_fn,
save_best_fn=save_best_fn,
reward_metric=reward_metric,
test_in_train=False,
).run()
return result, ma_policy
if __name__ == "__main__":
args = get_args()
args = get_env_info(args)
result, policy = train(args)
print(result)
调试方法
使用 VSCode 的 Python 调试配置 launch.json 如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
{
"version": "0.2.0",
"configurations": [
{
"name": "Python 调试程序: 包含参数的当前文件",
"type": "debugpy",
"request": "launch",
"program": "${workspaceFolder}/main.py",
"console": "integratedTerminal",
"args": []
}
]
}
找到 OffpolicyTrainer 中训练时执行 step 的位置
- 在
OffpolicyTrainer的run处转到定义 F12 ,进入run方法 - 在
run方法中deque(self, maxlen=0)处打断点 F9 ,在训练时智能体在此处与环境交互 - 运行调试 F5 程序在
deque(self, maxlen=0)处停止 - 单步调试 F11 ,进入
__iter__方法,此处用于重置OffpolicyTrainer的状态 - 单步跳出 Shift + F11 ,返回
deque(self, maxlen=0)处 - 单步调试 F11 ,进入
__next__方法,找到train_stat, update_stat, self.stop_fn_flag = self.training_step()行打断点 F9 此处为训练时执行step的位置 - 找到该位置后,即可删除
deque(self, maxlen=0)处的断点
找到 Tianshou PettingZooEnv 中 step 方法的位置
- 在
PettingZooEnv处转到定义 F12 ,进入PettingZooEnv类 - 找到该类中的
step方法,在self.env.step(action)处打断点 F9 此处为环境执行step的位置 - 禁用该断点,因为 Tianshou 在开始训练前会测试环境,如果不禁用该断点,程序会在不必要的时候暂停
正式进行单步调试
- 运行调试 F5 程序在
train_stat, update_stat, self.stop_fn_flag = self.training_step()处暂停 - 启用之前禁用的
PettingZooEnv中step方法的断点 - 继续调试 F5 ,程序在
PettingZooEnv中step方法处暂停
如果你想查看环境中具体的变化,可以单步调试 F11 ,此时就进入了 aec_rps.py 中 raw_env 的 step 方法。可以单步跳出 Shift + F11 ,返回 PettingZooEnv 中 step 方法。接着继续调试 F5 ,程序会回到 OffpolicyTrainer 的 __next__ 方法的 train_stat, update_stat, self.stop_fn_flag = self.training_step() 行,准备下一次决策。
如果你想直接跳转到下一次决策之前,可以继续调试
无论用上述两段中的哪一种方法执行一轮 train_stat, update_stat, self.stop_fn_flag = self.training_step() 后,进入调用堆栈中 main.py 的 train 方法,都可以通过监视 len(buffer) 和 print(buffer) 观察到 Experience buffer 增加了记录。
结果分析
为了方便观察,--buffer-size 的默认值设置为 6 。为了能观察到不同的情况,--epsilon-train 的默认值设置为 1.0 全随机。
环境每一步的状态变化如下表所示:
| Current Agent | Last Observation | Action | Rewards | 备注 | Cumulative Rewards | 备注 | ||
| agent_0 | agent_1 | agent_0 | agent_1 | |||||
| player_0 | 3 | 2 | 0 | 0 | 调用clear_rewards清空 | 0 | 0 | 清零当前智能体累计奖励后累加Rewards |
| player_1 | 3 | 1 | 1 | -1 | 所有智能体执行动作后计算结果 | 1 | -1 | 清零当前智能体累计奖励后累加Rewards |
| player_0 | 1 | 1 | 0 | 0 | 调用clear_rewards清空 | 0 | -1 | 清零当前智能体累计奖励后累加Rewards |
| player_1 | 2 | 2 | -1 | 1 | 所有智能体执行动作后计算结果 | -1 | 1 | 清零当前智能体累计奖励后累加Rewards |
| player_0 | 2 | 1 | 0 | 0 | 调用clear_rewards清空 | 0 | 1 | 清零当前智能体累计奖励后累加Rewards |
| player_1 | 1 | 1 | 0 | 0 | 所有智能体执行动作后计算结果 | 0 | 0 | 清零当前智能体累计奖励后累加Rewards |
Replay buffer 的内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
VectorReplayBuffer(
done: array([False, False, False, False, False, False]),
rew: array([[ 0., 0.],
[ 1., -1.],
[ 0., 0.],
[-1., 1.],
[ 0., 0.],
[ 0., 0.]]),
policy: Batch(
hidden_state: Batch(
player_0: Batch(),
player_1: Batch(),
),
),
truncated: array([False, False, False, False, False, False]),
act: array([2, 1, 1, 2, 1, 1]),
terminated: array([False, False, False, False, False, False]),
obs_next: Batch(
mask: array([[ True, True, True],
[ True, True, True],
[ True, True, True],
[ True, True, True],
[ True, True, True],
[ True, True, True]]),
agent_id: array(['player_1', 'player_0', 'player_1', 'player_0', 'player_1',
'player_0'], dtype=object),
obs: array([[0., 0., 0., 1.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 1., 0.],
[0., 1., 0., 0.],
[0., 1., 0., 0.]]),
),
info: Batch(
env_id: array([0, 0, 0, 0, 0, 0]),
),
obs: Batch(
mask: array([[ True, True, True],
[ True, True, True],
[ True, True, True],
[ True, True, True],
[ True, True, True],
[ True, True, True]]),
agent_id: array(['player_0', 'player_1', 'player_0', 'player_1', 'player_0',
'player_1'], dtype=object),
obs: array([[0., 0., 0., 1.],
[0., 0., 0., 1.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 1., 0.],
[0., 1., 0., 0.]]),
),
)
可以看出 Replay buffer 中按照 agent_id 区分了不同智能体的观测和动作。每条记录中保存了当前 step 所有智能体的奖励,无论是否所有智能体都执行了动作。
异步多智能体环境搭建方法
目前的环境是 player_0 和 player_1 依次执行动作。如果我们要设计的环境中每个 step 智能体会发生变化,而且执行决策的次数也不一致,那么应该如何实现?
下面通过魔改 PettingZoo AEC API 石头剪刀布环境为例,说明异步多智能体环境的搭建方法。
环境设计
假设环境中存在四个智能体 player_0 、player_1 、player_2 和 player_3 ,猜拳的次序为:player_0 和 player_1 比一轮,player_2 和 player_3 比两轮,以此循环。
代码实现
对于智能体可变的环境,需要参考 Knights Archers Zombies 环境的代码。
改动代码的关键在于:在 step 函数判断 self._agent_selector.is_last() (L750) 中,使用 self._agent_selector.reinit() (L765) 设定下一次参与猜拳的两个智能体。在设置奖励时,不参与猜拳的智能体的奖励设为 0 。