MindMaker - 基于虚幻引擎的深度强化学习仿真
如果在阅读时发现问题,欢迎在我的 GitHub Pages 仓库中提交 Issue 。
0 安装插件并创建工程
- 安装 MindMaker Machine Learning AI Plugin 插件到兼容的引擎上
- 该插件提供了用于与 Python 连接的 Socket IO 接口,使得状态信息和动作指令可以在虚幻引擎和 Python 之间传递
- 使用资产包 MindMaker: Deep Reinforcement Learning 创建工程,并命名为
MindMakerDRL- Python 脚本源码位于
MindMakerDRL/Content/MindMaker/Source(本文编写的 Python 脚本与该脚本略有不同,主要区别在于事件的命名和针对新版本依赖的更新) - 预编译好的可执行文件位于
MindMakerDRL/Content/MindMaker/dist/mindmaker
- Python 脚本源码位于
1 创建空白工程
- 虚幻项目浏览器 - 游戏 - 空白
- 项目名称:
DRLTutorial - 在
Content目录下创建_DRLTutorial文件夹作为项目目录 - 在
_DRLTutorial目录下创建Maps文件夹作为关卡目录 - 按 Ctr + S 保存当前关卡至
_DRLTutorial/Maps目录下,并命名为CartPole
2 偏好设置、关卡设置、插件设置
- Edit - Editor Preferences…
- General - Appearance - User Interface - Asset Editor Open Location: Main Window
- Edit - Project Settings…
- Project - Maps & Modes - Default Maps
- Editor Startup Map: CartPole
- Game Default Map: CartPole
- Edit - Plugins
- 搜索 MindMaker - 勾选 MindMaker
- 点击右下角 Restart Now
3 导入素材
- 在
Content目录下创建MindMaker文件夹作为素材目录 - 在资源管理器中,将
MindMakerDRL/Content/MindMaker目录下的Examples和MindMakerDRLStarterContent文件夹拷贝至DRLTutorial/Content/MindMaker中
4 创建 Cart 和 Pole 的蓝图
- 在
_DRLTutorial目录下创建Blueprints文件夹
4.1 创建 Cart 蓝图
- 在
Blueprints文件夹中右键 - Blueprint Class - 选择 Actor - 命名为BP_Cart - 双击
BP_Cart蓝图 - 在 Components 选项卡中添加
Static Mesh组件 - Details 选项卡- Static Mesh - Static Mesh - 选择
Cube - Transform - Scale - X: 2.0, Y: 2.0, Z: 0.5
- Static Mesh - Static Mesh - 选择
- 编译保存
4.2 创建 Pole 蓝图
- 在
Blueprints文件夹中右键 - Blueprint Class - 选择 Actor - 命名为BP_Pole - 双击
BP_Pole蓝图 - 在 Components 选项卡中添加
Static Mesh组件 - 命名为Cylinder- Details 选项卡- Static Mesh - Static Mesh - 选择
Cylinder - Transform - Scale - X: 1.0, Y: 1.0, Z: 5.0
- Static Mesh - Static Mesh - 选择
- 在 Components 选项卡中添加
Static Mesh组件 - 命名为Cone- Details 选项卡- Static Mesh - Static Mesh - 选择
Cone - Transform - Rotation - X: 180.0, Y: 0.0, Z: 0.0
- Transform - Scale - X: 1.0, Y: 1.0, Z: 0.1
- Static Mesh - Static Mesh - 选择
- 在 Components 选项卡中将
Coneattach toCylinder组件 - 调整
Cone的位置,将其接在Cylinder底部,并使坐标原点位于Cone的顶点 - 选中
Cylinder组件 - Details 选项卡 - Physics- Simulate Physics: True
- Mass (kg): 100
- 编译保存
5 将模型放入关卡
- 将
BP_Cart拖入关卡中 - Transform - Location - X: 1000, Y: 0, Z: 100 - 将
BP_Pole拖入关卡中 - Transform- Location - X: 1000, Y: 0, Z: 150
- Rotation - X: 20, Y: 0, Z: 0
- 选中关卡中的
PlayerStart- Transform - Rotation - 0, 0, 0
6 编写 Pole 蓝图程序
在 Pole 的倾角超过 30 度或训练结束时,将 Pole 重置至初始位置
变量表
| 变量名 | 类型 | 可见性 | 初始值 | 说明 |
|---|---|---|---|---|
CylinderRoll | Float | public | 0.0 | Cylinder 绕 X 轴的旋转角度(状态设置为公有变量方便观察) |
CylinderPitch | Float | public | 0.0 | Cylinder 绕 Y 轴的旋转角度(状态设置为公有变量方便观察) |
PoleReady | Boolean | private | True | Pole 是否处于初始位置 |
Cart | BP Cart (Object Reference) | public | None | 用于重置 Cart 的位置 |
- 在
BP_Cart蓝图中新建名为TrainingCompleted的 boolean 型 public 变量,默认值为 False ,用于指示训练是否结束 - 编译保存
- 如图所示编写程序

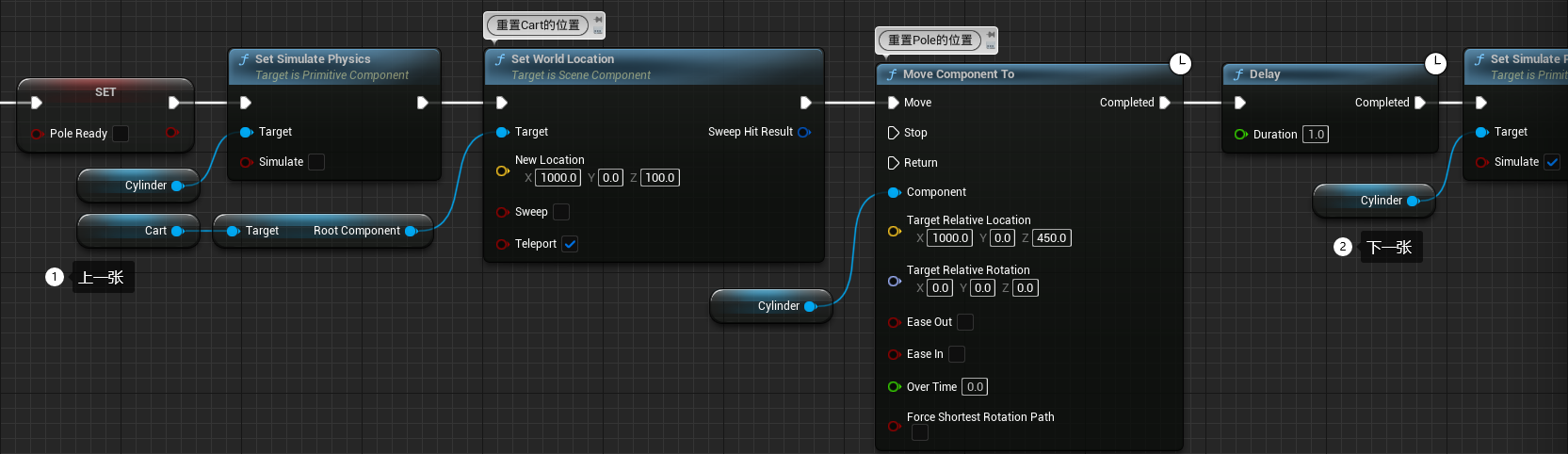
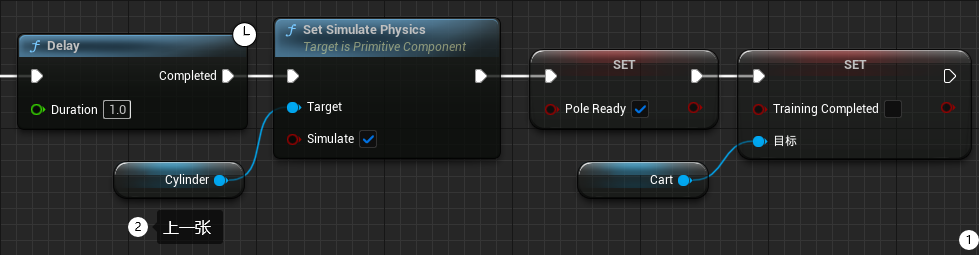
- 编译保存
- 在关卡中选中
BP_Pole- Details 选项卡 - Default - Cart - 选择BP_Cart
7 添加 DRL 参数
- 在
_DRLTutorial/Blueprints目录下创建DrlParameters文件夹 - 将
MindMaker/MindMakerDRLStarterContent/Assets/MindMakerDRLStarterContent目录下的 A2c Dqn Ddpg Sac Ppo Td3XXXCustomParameters_SC文件拷贝至DrlParameters中,并重命名为S_XXXCustomParameters用于区分 - 将上述目录下的
ActivationFunctions_SC拷贝至DrlParameters中,并重命名为E_ActivationFunctions - 将
S_XXXCustomParameters中的 activation func 参数类型改为E Activation Functions - 将上述目录下的
PolicyType_SC拷贝至DrlParameters中,并重命名为E_PolicyType - 将
S_XXXCustomParameters中的 policy 参数类型改为E Policy Type - 将上述目录下的
LearningAlgorithms_SC拷贝至Blueprints中,并重命名为E_LearningAlgorithms
8 编写 Cart 蓝图程序
- 在
BP_Cart蓝图中的 Components 选项卡中添加Socket IOClient组件
变量表
| 行号 | 变量名 | 类型 | 可见性 | 初始值 | 说明 |
|---|---|---|---|---|---|
| 1 | TrainingCompleted | Boolean | private | False | 指示训练是否结束(在编写 Pole 蓝图程序时已添加) |
| 2 | MindMakerStructure | S Mind Maker Custom Struct | private | None | 用于向 Python 脚本发送状态向量和 reward |
| 3 | MinActionVal | Float | private | 0.0 | 动作的最小值 |
| 4 | MaxActionVal | Float | private | 0.0 | 动作的最大值 |
| 5 | Reward | Float | private | 0.0 | 环境中的奖励 |
| 6 | Observations | String | private | None | 环境中的观测值 |
| 7 | ActionSelected | Float | private | 0.0 | 已选择的动作 |
| 8 | ActionReceived | Boolean | private | False | 指示是否收到动作 |
| 9 | Pole | BP Pole (Object Reference) | public | None | 用于获取杆的倾角 |
| 10 | done | Boolean | private | False | 用于指示当前 episode 是否完成;应当在 BP_Cart 的 CheckReward 函数中置 true ;在 BP_Pole 重置场景时置 false ;CartPole 任务不需要设置 done ,所以没有连接 |
| 11 | NumTrainingEpisodes | Integer | private | 3000 | 训练的 episode 数量 |
| 12 | NumEvalEpisodes | Integer | private | 300 | 评估的 episode 数量 |
| 13 | A2cParams | S A2c Custom Parameters | private | None | 用于保存 A2c 算法的参数 |
| 14 | DqnParams | S Dqn Custom Parameters | private | None | 用于保存 Dqn 算法的参数 |
| 15 | DdpgParams | S Ddpg Custom Parameters | private | None | 用于保存 Ddpg 算法的参数 |
| 16 | SacParams | S Sac Custom Parameters | private | None | 用于保存 Sac 算法的参数 |
| 17 | PpoParams | S Ppo Custom Parameters | private | None | 用于保存 Ppo 算法的参数 |
| 18 | Td3Params | S Td3 Custom Parameters | private | None | 用于保存 Td3 算法的参数 |
8.1 编写 LaunchMindMaker 函数
- My Blueprint 选项卡 - FUNCTIONS - 右侧
+- 命名为LaunchMindMaker - Details 选项卡 - Inputs - 右侧
+- 创建 19 个变量(见下方输入变量表) - 将
MindMaker/MindMakerDRLStarterContent/Assets/MindMakerDRLStarterContent目录下的MindMakerCustomStruct_SC拷贝至Blueprints,并重命名为S_MindMakerCustomStruct,修改结构体中的成员变量类型为第 7 章中拷贝后的名字 - 在 My Blueprint 选项卡中添加变量表中第 2-6 行的变量
- 添加
Set members in S_MindMakerCustomStruct节点 - Details 选项卡 - Pin Options - Default Category - 将所有的 (As pin) 设为 True - 如图所示连接端口和节点
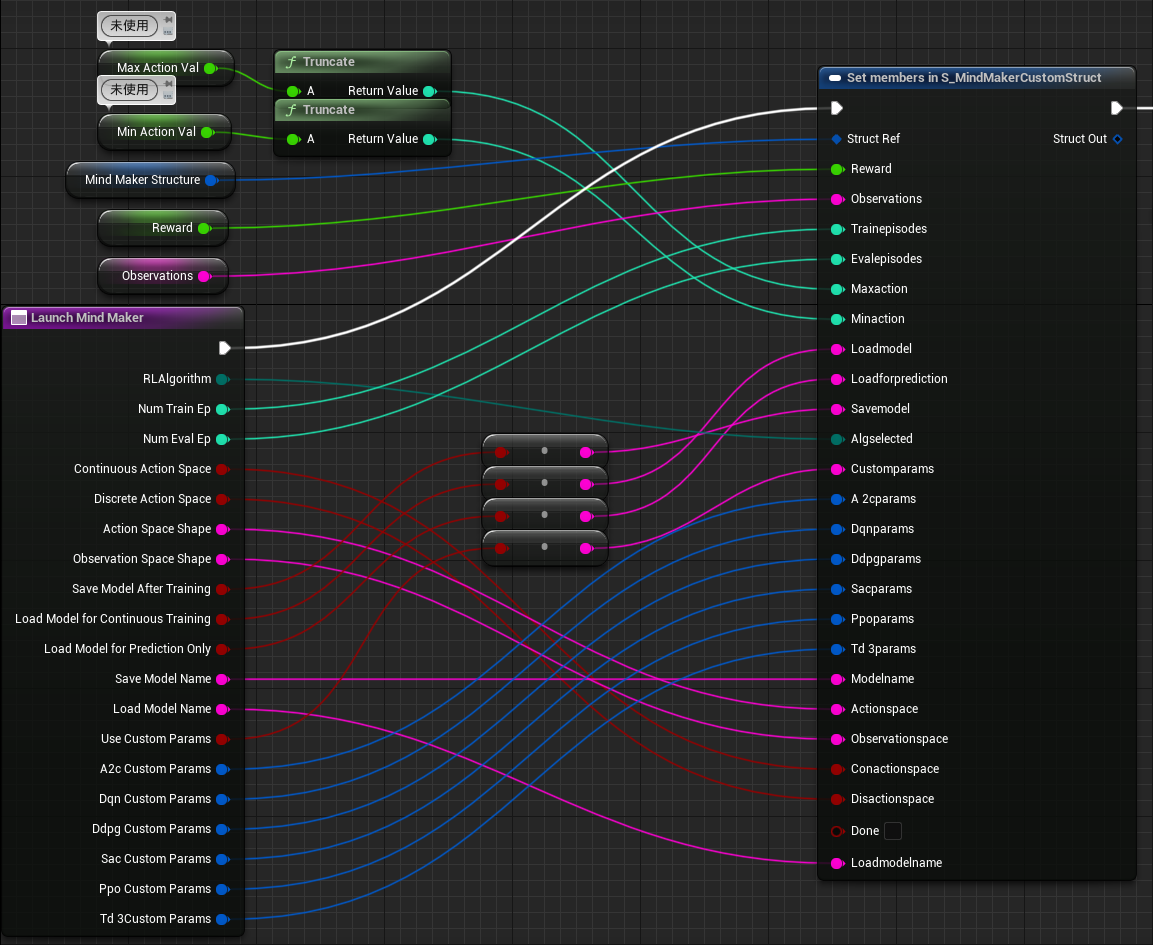

输入变量表
| 变量名 | 类型 |
|---|---|
RLAlgorithm | E Learning Algorithms |
NumTrainEp | Integer |
NumEvalEp | Integer |
ContinuousActionSpace | Boolean |
DiscreteActionSpace | Boolean |
ActionSpaceShape | String |
ObservationSpaceShape | String |
SaveModelAfterTraining | Boolean |
LoadModelForContinuousTraining | Boolean |
LoadModelForPredictionOnly | Boolean |
SaveModelName | String |
LoadModelName | String |
UseCustomParams | Boolean |
A2cCustomParams | S A2c Custom Parameters |
DqnCustomParams | S Dqn Custom Parameters |
DdpgCustomParams | S Ddpg Custom Parameters |
SacCustomParams | S Sac Custom Parameters |
PpoCustomParams | S Ppo Custom Parameters |
Td3CustomParams | S Td 3Custom Parameters |
8.2 编写 ReceiveAction 函数
- 右键 Event Graph 空白处 - Add Custom Event… - 命名为
DisplayAction - My Blueprint 选项卡 - FUNCTIONS - 右侧
+- 命名为ReceiveAction - Details 选项卡 - Inputs - 右侧
+- 创建名为Message的SIOJson Value (Object Reference型变量 - 在 My Blueprint 选项卡中添加变量表中第 7-8 行的变量
- 如图所示连接节点

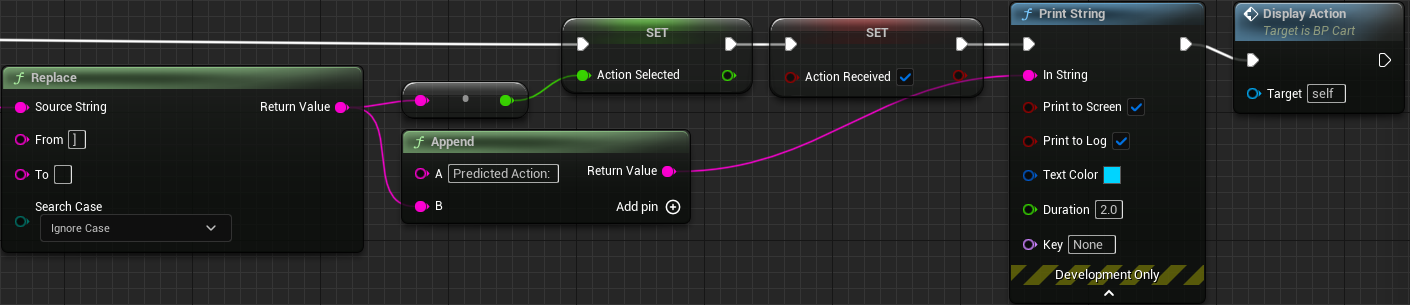
8.3 编写 MakeObservations 函数
- My Blueprint 选项卡 - FUNCTIONS - 右侧
+- 命名为MakeObservations - 在 My Blueprint 选项卡中添加变量表中第 9 行的变量
- 如图所示连接节点
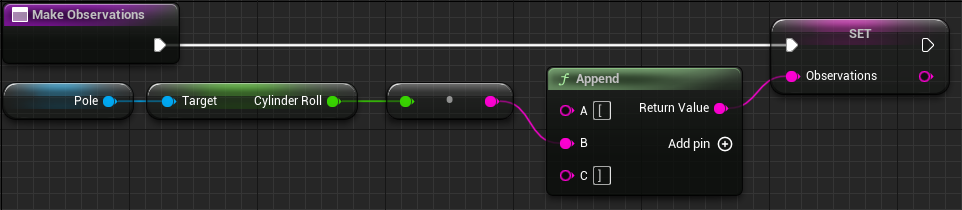
- 编译保存
- 在关卡中选中
BP_Cart- Details 选项卡 - Default - Pole - 选择BP_Pole
8.4 编写 CheckReward 函数
- My Blueprint 选项卡 - FUNCTIONS - 右侧
+- 命名为CheckReward - 在 My Blueprint 选项卡中添加变量表中第 10 行的变量
- 如图所示连接节点

8.5 编写 MessageHandler 函数
- My Blueprint 选项卡 - FUNCTIONS - 右侧
+- 命名为MessageHandler - Details 选项卡 - Inputs - 右侧
+- 创建名为Message的SIOJson Value (Object Reference型变量 - 如图所示连接节点

8.6 编写 Event Graph
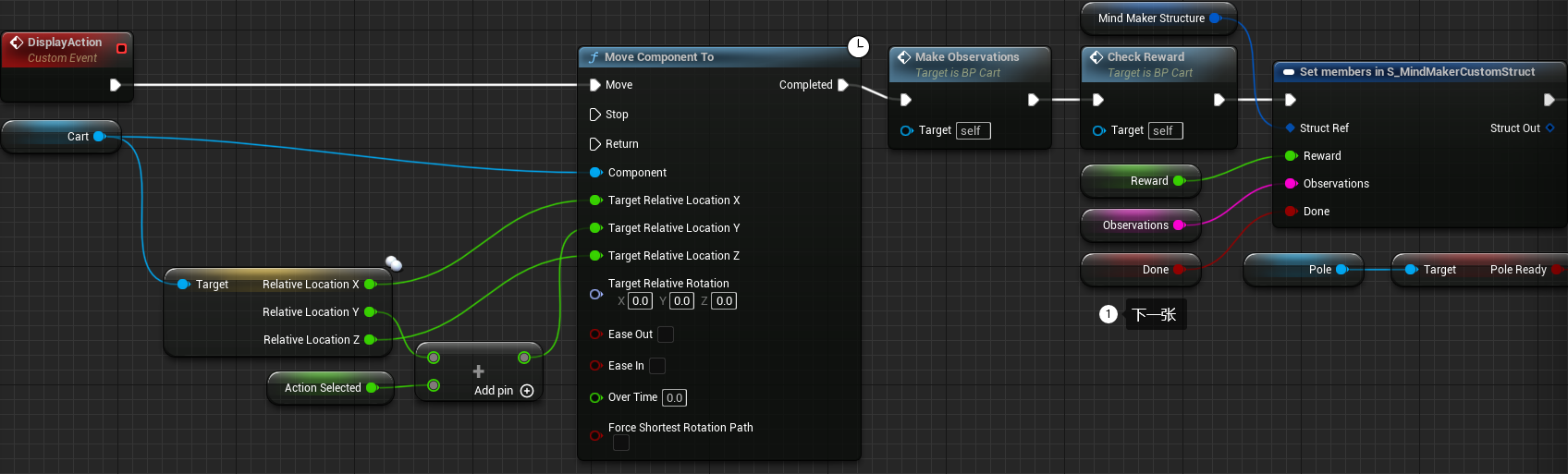
8.6.1 编写 ReceiveAction 函数 调用的 DisplayAction 事件
- 添加
Set members in S_MindMakerCustomStruct节点 - Details 选项卡 - Pin Options - Default Category- reward: true
- observations: true
- done: true
- 如图所示连接节点
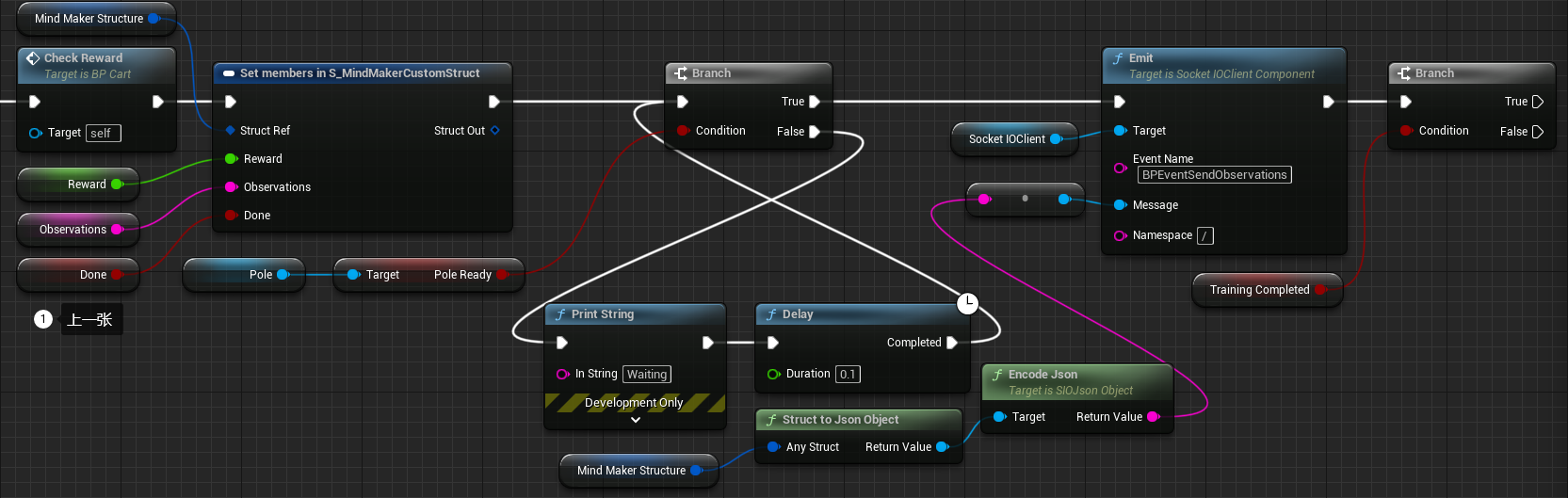
8.6.2 编写 Event BeginPlay 事件
Mind Maker Windows 节点会自动寻找
MindMakerDRL/Content/MindMaker/dist/mindmaker目录下的mindmaker.exe文件
如果文件存在,则会自动启动mindmaker.exe
否则会等待 Python 脚本的 Socket 连接
- 如图所示连接节点

8.6.3 编写 On Connected (SocketIOClient) 事件
- 点击 Components 选项卡中的 SocketIOClient 组件 - Details 选项卡 - Events - On Connected - 点击右侧
+ - 在 My Blueprint 选项卡中添加变量表中第 11-18 行的变量
- 如图所示连接节点

此处使用 PPO 算法,因此只列出了 PPO 算法的参数
| Key | Value |
|---|---|
| policy | MlpPolicy |
| learning rate | 0.00025 |
| n steps | 128 |
| batch size | 64 |
| n epochs | 4 |
| gamma | 0.99 |
| gae lambda | 0.0 |
| clip range | 0.2 |
| clip range vf | None |
| normalize advantage | False |
| ent coef | 0.01 |
| vf coef | 0.5 |
| max grad norm | 0.5 |
| use sde | False |
| sde sample freq | 0 |
| target kl | None |
| tensorboard log | None |
| create eval env | False |
| verbose | 1 |
| seed | 0 |
| device | auto |
| init setup model | True |
| activation func | th.nn.Tanh |
| network arch | [128,128] |
8.6.4 编写 On Disconnected (SocketIOClient) 事件
- 点击 Components 选项卡中的 SocketIOClient 组件 - Details 选项卡 - Events - On Disconnected - 点击右侧
+ - 如图所示连接节点

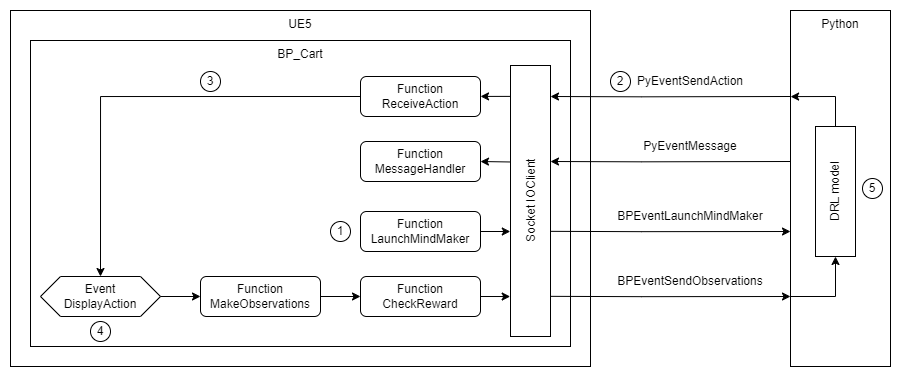
9 UE5 与 Python 的通讯流程
- 在 UE5 与 Python 建立连接时,
BP_Cart蓝图中执行初始化- 将
PyEventSendAction事件绑定给ReceiveAction函数处理 - 将
PyEventMessage事件绑定给MessageHandler函数处理 - 调用
LaunchMindMaker函数,将初始化参数通过BPEventLaunchMindMaker事件发送给 Python
- 将
- Python 通过
PyEventSendAction触发ReceiveAction函数的调用 ReceiveAction函数触发DisplayAction事件DisplayAction事件调用MakeObservations函数和CheckReward函数,获得执行完动作后的 state 和 reward ,并通过BPEventSendObservations发送给 Python- Python 根据 state 得到下一个 action ,进入下一轮 2-5 的循环
10 编写 Python 脚本
10.1 安装依赖
1
2
3
4
5
6
7
8
9
10
11
conda create -n MindMaker python=3.10
conda activate MindMaker
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install tensorboard
pip install stable-baselines3
pip install gym
pip install flask
pip install python-socketio
pip install eventlet
pip install gevent
pip install shimmy
10.2 编写代码
与资产包 MindMaker: Deep Reinforcement Learning 原版代码相比,修改了事件名称
1 2 3 4
"launchmindmaker" -> "BPEventLaunchMindMaker" "sendobs" -> "BPEventSendObservations" "recaction" -> "PyEventSendAction" "messages" -> "PyEventMessage"
在 gym 0.26.X 中,环境类需要有一个
seed方法,用于设置随机数生成器的种子,以便实现可复现的结果。这在之前的 gym 版本中可能不是强制性的,但在新版本中是必需的。可以简单地在UnrealEnvWrap类中添加一个不执行任何操作的seed方法。1 2
def seed(self, seed=None): pass # 由于不需要控制随机性,此方法为空
查看代码
记得删除第一行和最后一行的代码块标记
```python
# (c) Copywrite 2020 Aaron Krumins
import ast
import json
import logging.handlers
import os
import sys
from random import randint
import gym
import numpy as np
import socketio
import torch as th
from flask import Flask
from gym import spaces
from stable_baselines3 import A2C, DQN, SAC, TD3
from stable_baselines3.common.env_util import make_vec_env
from stable_baselines3.common.noise import (
NormalActionNoise,
OrnsteinUhlenbeckActionNoise,
)
from stable_baselines3.dqn.policies import MlpPolicy as DqnMlpPolicy
from stable_baselines3.sac.policies import MlpPolicy as SacMlpPolicy
from stable_baselines3.td3.policies import MlpPolicy as Td3MlpPolicy
from tensorboard import version
print("TensorBoard version:", version.VERSION)
"""
set async_mode to 'threading', 'eventlet', 'gevent' or 'gevent_uwsgi'
to force a mode, else the best mode is selected automatically
from what's installed
"""
# async_mode = None # 未使用
# thread = None # 未使用
sio = socketio.Server(logger=True, async_mode="eventlet")
app = Flask(__name__)
app.wsgi_app = socketio.WSGIApp(sio, app.wsgi_app)
Observations = "None"
UEReward = "0"
UEDone = False
MaxActions = 0
LocalReward = 0
ObservationFlag = 0
# inf = math.inf
ActionSpace = "None"
ObservationSpace = "None"
ResultDir = os.getenv("APPDATA")
ConActionSpace = ""
DisActionSpace = ""
class UnrealEnvWrap(gym.Env):
"""
Custom Environment that follows gym interface.
This is an env wrapper that receives any environmental variables from UE and shapes into a format for OpenAI Gym.
"""
# Because of google colab, we cannot implement the GUI ('human' render mode)
metadata = {"render.modes": ["console"]}
def __init__(self):
super().__init__()
global MaxActions
global ConActionSpace
global DisActionSpace
global ActionSpace
global ObservationSpace
print("Class: " + UnrealEnvWrap.__name__ + " constructor called")
print(f"{ConActionSpace=} | {DisActionSpace=} | {ActionSpace=}")
if ConActionSpace:
print("continuous action space")
ActionSpace = "spaces.Box(" + ActionSpace + ")"
ObservationSpace = "spaces.Box(" + ObservationSpace + ")"
self.action_space = eval(ActionSpace)
self.observation_space = eval(ObservationSpace)
# Initialize the agent with a random action
self.agent_pos = randint(0, 100)
elif DisActionSpace:
print("discrete action space")
# Initialize the agent with a random action
ActionSpace = int(ActionSpace)
self.agent_pos = randint(0, ActionSpace)
# Define action and observation space
# They must be gym.spaces objects
# Example when using discrete actions, we have two: left and right
n_actions = ActionSpace
self.action_space = spaces.Discrete(n_actions)
ObservationSpace = "spaces.Box(" + ObservationSpace + ")"
# The observation will be all environment variables from UE that agent is tracking
self.observation_space = eval(ObservationSpace)
else:
log_message = "No action space type selected"
sio.emit("PyEventMessage", log_message)
def reset(self):
"""
Important: the observation must be a numpy array
:return: (np.array)
"""
# Initialize the agent with a random action
self.observation_space = [0]
# here we convert to float32 to make it more general (in case we want to use continuous actions)
return np.array([self.observation_space])
# sending actions to UE and receiving observations in response to those actions
def step(self, action):
global Observations
global LocalReward
global UEReward
global UEDone
global ObservationFlag
ObservationFlag = 0
# send actions to UE as they are chosen by the RL algorithm
str_action = str(action)
print("action:", str_action)
sio.emit("PyEventSendAction", str_action)
# After sending action, we enter a pause loop until we receive a response from UE with the observations
for _ in range(10000):
if ObservationFlag == 1:
ObservationFlag = 0
break
else:
sio.sleep(0.06)
# load the observations received from UE
array_obs = ast.literal_eval(Observations)
self.observation_space = array_obs
print(array_obs)
done = bool(UEDone)
LocalReward = float(UEReward)
print("reward:", LocalReward)
print(UEDone)
if done:
print("I'm restarting now how fun")
LocalReward = 0
# Optionally we can pass additional info, we are not using that for now
info = {}
return (
np.array([self.observation_space]).astype(np.float32),
LocalReward,
done,
info,
)
def seed(self, seed=None):
# 在 Gym 0.26.2 中,环境类需要有一个 seed 方法,用于设置随机数生成器的种子,以便实现可复现的结果。
# 这在之前的 Gym 版本中可能不是强制性的,但在新版本中是必需的。
pass
def render(self, mode="console"):
if mode != "console":
raise NotImplementedError()
def close(self):
exit(1)
@sio.event
def disconnect_request(sid):
sio.disconnect(sid)
exit()
@sio.event
def connect(*_):
print("Connected To Unreal Engine")
@sio.event
def disconnect(_):
print("Disconnected From Unreal Engine, Exiting MindMaker")
@sio.on("BPEventLaunchMindMaker")
def MindMakerInitializer(sid, data):
global UEDone
global LocalReward
global MaxActions
global ConActionSpace
global DisActionSpace
global ActionSpace
global ObservationSpace
json_input = json.loads(data)
ConActionSpace = json_input["conactionspace"]
DisActionSpace = json_input["disactionspace"]
ActionSpace = json_input["actionspace"]
ObservationSpace = json_input["observationspace"]
train_episodes = json_input["trainepisodes"]
eval_episodes = json_input["evalepisodes"]
load_model = json_input["loadmodel"]
save_model = json_input["savemodel"]
model_name = json_input["modelname"]
alg_selected = json_input["algselected"]
use_custom_params = json_input["customparams"]
a2c_params = json_input["a2cparams"]
dqn_params = json_input["dqnparams"]
ddpg_params = json_input["ddpgparams"]
ppo_params = json_input["ppoparams"]
sac_params = json_input["sacparams"]
td3_params = json_input["td3params"]
load_for_prediction = json_input["loadforprediction"]
load_model_name = json_input["loadmodelname"]
UEDone = json_input["done"]
env = UnrealEnvWrap()
env = make_vec_env(lambda: env, n_envs=1) # wrap it
print("save model value:", save_model)
print("load model value:", load_model)
print("Total Training Episodes:", train_episodes)
save_path = os.path.join(ResultDir, model_name)
load_path = os.path.join(ResultDir, load_model_name)
if load_model == "true":
# Load the trained agent
if alg_selected == "DQN":
model = DQN.load(load_path, env=env)
elif alg_selected == "A2C":
model = A2C.load(load_path, env=env)
elif alg_selected == "DDPG":
from stable_baselines3 import DDPG
from stable_baselines3.ddpg.policies import MlpPolicy as DdpgMlpPolicy
model = DDPG.load(load_path, env=env)
elif alg_selected == "PPO":
from stable_baselines3 import PPO
model = PPO.load(load_path, env=env)
elif alg_selected == "SAC":
model = SAC.load(load_path, env=env)
elif alg_selected == "TD3":
model = TD3.load(load_path, env=env)
else:
model = {}
log_message = "Loading the Agent for Continuous Training"
print(log_message)
sio.emit("PyEventMessage", log_message)
model.learn(total_timesteps=train_episodes)
if save_model == "true":
# Save the agent
model.save(save_path)
log_message = "The trained model was saved"
print(log_message)
sio.emit("PyEventMessage", log_message)
quit()
if load_for_prediction == "true":
# Load the trained agent
if alg_selected == "DQN":
model = DQN.load(load_path)
elif alg_selected == "A2C":
model = A2C.load(load_path)
elif alg_selected == "DDPG":
from stable_baselines3 import DDPG
from stable_baselines3.ddpg.policies import MlpPolicy as DdpgMlpPolicy
model = DDPG.load(load_path)
elif alg_selected == "PPO":
from stable_baselines3 import PPO
model = PPO.load(load_path)
elif alg_selected == "SAC":
model = SAC.load(load_path)
elif alg_selected == "TD3":
model = TD3.load(load_path)
else:
model = {}
log_message = "Loading the Agent for Prediction"
print(log_message)
sio.emit("PyEventMessage", log_message)
env.render(mode="console")
obs = env.reset()
eval_complete = eval_episodes + 2
print(eval_complete)
for step in range(eval_complete):
action, _ = model.predict(obs, deterministic=True)
int_action = action[0]
print("Action:", int_action)
obs, LocalReward, done, info = env.step(action)
print("obs=", obs, "reward=", LocalReward, "done=", done)
if step == eval_episodes:
print(step)
log_message = "Evaluation Complete"
sio.emit("PyEventMessage", log_message)
quit()
else:
# Train the agent with different algorithms from stable baselines
print("algorithm selected:", alg_selected)
print("use custom params:", use_custom_params)
if (alg_selected == "DQN") and (use_custom_params == "true"):
learning_rate = dqn_params["learning rate"]
buffer_size = dqn_params["buffer size"]
learning_starts = dqn_params["learning starts"]
batch_size = dqn_params["batch size"]
tau = dqn_params["tau"]
gamma = dqn_params["gamma"]
train_freq = dqn_params["train freq"]
gradient_steps = dqn_params["gradient steps"]
replay_buffer_class = dqn_params["replay buffer class"]
replay_buffer_kwargs = dqn_params["replay buffer kwargs"]
optimize_memory_usage = dqn_params["optimize memory usage"]
target_update_interval = dqn_params["target update interval"]
exploration_fraction = dqn_params["exploration fraction"]
exploration_initial_eps = dqn_params["exploration initial eps"]
exploration_final_eps = dqn_params["exploration final eps"]
max_grad_norm = dqn_params["max grad norm"]
tensorboard_log = dqn_params["tensorboard log"]
create_eval_env = dqn_params["create eval env"]
verbose = dqn_params["verbose"]
seed = dqn_params["seed"]
device = dqn_params["device"]
_init_setup_model = dqn_params["init setup model"]
policy = dqn_params["policy"]
act_func = dqn_params["activation func"]
network_arch = dqn_params["network arch"]
# CAN ONLY PASS IN SINGLE ARGUMENT VALUES FOR NETWORK ARCH, NO DICTS
if act_func == "th.nn.ReLU":
policy_kwargs = dict(
activation_fn=th.nn.ReLU, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.LeakyReLU":
policy_kwargs = dict(
activation_fn=th.nn.LeakyReLU,
net_arch=ast.literal_eval(network_arch),
)
elif act_func == "th.nn.Tanh":
policy_kwargs = dict(
activation_fn=th.nn.Tanh, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.ReLU6":
policy_kwargs = dict(
activation_fn=th.nn.ReLU6, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.SELU":
policy_kwargs = dict(
activation_fn=th.nn.SELU, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.ELU":
policy_kwargs = dict(
activation_fn=th.nn.ELU, net_arch=ast.literal_eval(network_arch)
)
else:
policy_kwargs = dict(net_arch=ast.literal_eval(network_arch))
model = DQN(
policy,
env,
gamma=gamma,
learning_rate=learning_rate,
verbose=verbose,
tensorboard_log=tensorboard_log,
_init_setup_model=_init_setup_model,
seed=seed,
buffer_size=buffer_size,
exploration_fraction=exploration_fraction,
exploration_final_eps=exploration_final_eps,
exploration_initial_eps=exploration_initial_eps,
batch_size=batch_size,
tau=tau,
train_freq=train_freq,
gradient_steps=gradient_steps,
replay_buffer_class=ast.literal_eval(replay_buffer_class),
replay_buffer_kwargs=ast.literal_eval(replay_buffer_kwargs),
optimize_memory_usage=optimize_memory_usage,
target_update_interval=target_update_interval,
max_grad_norm=max_grad_norm,
create_eval_env=create_eval_env,
device=device,
learning_starts=learning_starts,
policy_kwargs=policy_kwargs,
)
print("Custom DQN training in process...")
model.learn(total_timesteps=train_episodes)
if save_model == "true":
# Save the agent
model.save(save_path)
print("Saving the Trained Agent")
elif alg_selected == "DQN":
model = DQN("MlpPolicy", env, verbose=1)
print("DQN training in process...")
model.learn(total_timesteps=train_episodes)
if save_model == "true":
# Save the agent
model.save(save_path)
print("Saving the Trained Agent")
elif (alg_selected == "A2C") and (use_custom_params == "true"):
policy = a2c_params["policy"]
learning_rate = a2c_params["learning rate"]
n_steps = a2c_params["n steps"]
gamma = a2c_params["gamma"]
gae_lambda = a2c_params["gae lambda"]
ent_coef = a2c_params["ent coef"]
vf_coef = a2c_params["vf coef"]
max_grad_norm = a2c_params["max grad norm"]
rms_prop_eps = a2c_params["rms prop eps"]
use_rms_prop = a2c_params["use rms prop"]
use_sde = a2c_params["use sde"]
sde_sample_freq = a2c_params["sde sample freq"]
normalize_advantage = a2c_params["normalize advantage"]
tensorboard_log = a2c_params["tensorboard log"]
create_eval_env = a2c_params["create eval env"]
verbose = a2c_params["verbose"]
seed = a2c_params["seed"]
device = a2c_params["device"]
_init_setup_model = a2c_params["init setup model"]
act_func = a2c_params["activation func"]
network_arch = a2c_params["network arch"]
# CAN ONLY PASS IN SINGLE ARGUMENT VALUES FOR NETWORK ARCH, NO DICTS
if act_func == "th.nn.ReLU":
policy_kwargs = dict(
activation_fn=th.nn.ReLU, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.LeakyReLU":
policy_kwargs = dict(
activation_fn=th.nn.LeakyReLU,
net_arch=ast.literal_eval(network_arch),
)
elif act_func == "th.nn.Tanh":
policy_kwargs = dict(
activation_fn=th.nn.Tanh, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.ReLU6":
policy_kwargs = dict(
activation_fn=th.nn.ReLU6, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.SELU":
policy_kwargs = dict(
activation_fn=th.nn.SELU, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.ELU":
policy_kwargs = dict(
activation_fn=th.nn.ELU, net_arch=ast.literal_eval(network_arch)
)
else:
policy_kwargs = dict(net_arch=ast.literal_eval(network_arch))
model = A2C(
policy=policy,
env=env,
learning_rate=learning_rate,
n_steps=n_steps,
gamma=gamma,
gae_lambda=gae_lambda,
ent_coef=ent_coef,
vf_coef=vf_coef,
max_grad_norm=max_grad_norm,
rms_prop_eps=rms_prop_eps,
use_rms_prop=use_rms_prop,
use_sde=use_sde,
sde_sample_freq=sde_sample_freq,
normalize_advantage=normalize_advantage,
tensorboard_log=tensorboard_log,
create_eval_env=create_eval_env,
policy_kwargs=policy_kwargs,
verbose=verbose,
seed=seed,
device=device,
_init_setup_model=_init_setup_model,
)
print("Custom A2C training in process...")
model.learn(total_timesteps=train_episodes)
if save_model == "true":
# Save the agent
model.save(save_path)
print("Saving the Trained Agent")
elif alg_selected == "A2C":
model = A2C("MlpPolicy", env, verbose=1)
print("A2C training in process...")
model.learn(total_timesteps=train_episodes)
if save_model == "true":
# Save the agent
model.save(save_path)
print("Saving the Trained Agent")
elif (alg_selected == "DDPG") and (use_custom_params == "true"):
from stable_baselines3 import DDPG
from stable_baselines3.ddpg.policies import MlpPolicy as DdpgMlpPolicy
policy = ddpg_params["policy"]
learning_rate = ddpg_params["learning rate"]
buffer_size = ddpg_params["buffer size"]
learning_starts = ddpg_params["learning starts"]
batch_size = ddpg_params["batch size"]
tau = ddpg_params["tau"]
gamma = ddpg_params["gamma"]
train_freq = ddpg_params["train freq"]
gradient_steps = ddpg_params["gradient steps"]
action_noise = ddpg_params["action noise"]
replay_buffer_class = ddpg_params["replay buffer class"]
replay_buffer_kwargs = ddpg_params["replay buffer kwargs"]
optimize_memory_usage = ddpg_params["optimize memory usage"]
create_eval_env = ddpg_params["create eval env"]
verbose = ddpg_params["verbose"]
seed = ddpg_params["seed"]
device = ddpg_params["device"]
_init_setup_model = ddpg_params["init setup model"]
tensorboard_log = ddpg_params["tensorboard log"]
act_func = ddpg_params["activation func"]
network_arch = ddpg_params["network arch"]
# CAN ONLY PASS IN SINGLE ARGUMENT VALUES FOR NETWORK ARCH, NO DICTS
if act_func == "th.nn.ReLU":
policy_kwargs = dict(
activation_fn=th.nn.ReLU, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.LeakyReLU":
policy_kwargs = dict(
activation_fn=th.nn.LeakyReLU,
net_arch=ast.literal_eval(network_arch),
)
elif act_func == "th.nn.Tanh":
policy_kwargs = dict(
activation_fn=th.nn.Tanh, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.ReLU6":
policy_kwargs = dict(
activation_fn=th.nn.ReLU6, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.SELU":
policy_kwargs = dict(
activation_fn=th.nn.SELU, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.ELU":
policy_kwargs = dict(
activation_fn=th.nn.ELU, net_arch=ast.literal_eval(network_arch)
)
else:
policy_kwargs = dict(net_arch=ast.literal_eval(network_arch))
model = DDPG(
policy,
env,
learning_rate=learning_rate,
buffer_size=buffer_size,
learning_starts=learning_starts,
batch_size=batch_size,
tau=tau,
gamma=gamma,
train_freq=ast.literal_eval(train_freq),
gradient_steps=gradient_steps,
action_noise=ast.literal_eval(action_noise),
replay_buffer_class=ast.literal_eval(replay_buffer_class),
replay_buffer_kwargs=ast.literal_eval(replay_buffer_kwargs),
optimize_memory_usage=optimize_memory_usage,
tensorboard_log=tensorboard_log,
create_eval_env=create_eval_env,
verbose=verbose,
seed=ast.literal_eval(seed),
device=device,
_init_setup_model=_init_setup_model,
policy_kwargs=policy_kwargs,
)
print("Custom DDPG training in process...")
model.learn(total_timesteps=train_episodes)
print("DDPG training complete")
if save_model == "true":
# Save the agent
model.save(save_path)
print("Saving the Trained Agent")
elif alg_selected == "DDPG":
from stable_baselines3 import DDPG
from stable_baselines3.ddpg.policies import MlpPolicy as DdpgMlpPolicy
# the noise objects for DDPG
n_actions = env.action_space.shape[-1]
action_noise = OrnsteinUhlenbeckActionNoise(
mean=np.zeros(n_actions), sigma=float(0.5) * np.ones(n_actions)
)
model = DDPG(DdpgMlpPolicy, env, verbose=1, action_noise=action_noise)
print("DDPG training in process...")
model.learn(total_timesteps=train_episodes)
print("DDPG training complete")
if save_model == "true":
# Save the agent
model.save(save_path)
print("Saving the Trained Agent")
elif (alg_selected == "PPO") and (use_custom_params == "true"):
from stable_baselines3 import PPO
policy = ppo_params["policy"]
learning_rate = ppo_params["learning rate"]
n_steps = ppo_params["n steps"]
batch_size = ppo_params["batch size"]
n_epochs = ppo_params["n epochs"]
gamma = ppo_params["gamma"]
gae_lambda = ppo_params["gae lambda"]
clip_range = ppo_params["clip range"]
clip_range_vf = ppo_params["clip range vf"]
normalize_advantage = ppo_params["normalize advantage"]
ent_coef = ppo_params["ent coef"]
vf_coef = ppo_params["vf coef"]
max_grad_norm = ppo_params["max grad norm"]
use_sde = ppo_params["use sde"]
sde_sample_freq = ppo_params["sde sample freq"]
target_kl = ppo_params["target kl"]
tensorboard_log = ppo_params["tensorboard log"]
create_eval_env = ppo_params["create eval env"]
verbose = ppo_params["verbose"]
seed = ppo_params["seed"]
device = ppo_params["device"]
_init_setup_model = ppo_params["init setup model"]
act_func = ppo_params["activation func"]
network_arch = ppo_params["network arch"]
# CAN ONLY PASS IN SINGLE ARGUMENT VALUES FOR NETWORK ARCH, NO DICTS
if act_func == "th.nn.ReLU":
policy_kwargs = dict(
activation_fn=th.nn.ReLU, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.LeakyReLU":
policy_kwargs = dict(
activation_fn=th.nn.LeakyReLU,
net_arch=ast.literal_eval(network_arch),
)
elif act_func == "th.nn.Tanh":
policy_kwargs = dict(
activation_fn=th.nn.Tanh, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.ReLU6":
policy_kwargs = dict(
activation_fn=th.nn.ReLU6, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.SELU":
policy_kwargs = dict(
activation_fn=th.nn.SELU, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.ELU":
policy_kwargs = dict(
activation_fn=th.nn.ELU, net_arch=ast.literal_eval(network_arch)
)
else:
policy_kwargs = dict(net_arch=ast.literal_eval(network_arch))
model = PPO(
policy,
env,
learning_rate=learning_rate,
n_steps=n_steps,
batch_size=batch_size,
gamma=gamma,
gae_lambda=gae_lambda,
clip_range=clip_range,
clip_range_vf=ast.literal_eval(clip_range_vf),
normalize_advantage=normalize_advantage,
ent_coef=ent_coef,
vf_coef=vf_coef,
max_grad_norm=max_grad_norm,
use_sde=use_sde,
sde_sample_freq=sde_sample_freq,
tensorboard_log=tensorboard_log,
# create_eval_env=create_eval_env, # 当前版本的 stable_baselines3 没有 create_eval_env 参数
policy_kwargs=policy_kwargs,
verbose=verbose,
seed=seed,
device=device,
_init_setup_model=_init_setup_model,
)
print("Custom PPO training in process...")
model.learn(total_timesteps=train_episodes)
print("PPO training complete")
if save_model == "true":
# Save the agent
save_path = ResultDir + "\\" + model_name
model.save(save_path)
print("Saving the Trained Agent")
log_message = "The trained model was saved"
sio.emit("PyEventMessage", log_message)
elif alg_selected == "PPO":
from stable_baselines3 import PPO
model = PPO("MlpPolicy", env, verbose=1)
print("PPO training in process...")
model.learn(total_timesteps=train_episodes)
print("PPO training complete")
if save_model == "true":
# Save the agent
model.save(save_path)
print("Saving the Trained Agent")
log_message = "The trained model was saved"
sio.emit("PyEventMessage", log_message)
elif (alg_selected == "SAC") and (use_custom_params == "true"):
policy = sac_params["policy"]
learning_rate = sac_params["learning rate"]
buffer_size = sac_params["buffer size"]
learning_starts = sac_params["learning starts"]
batch_size = sac_params["batch size"]
tau = sac_params["tau"]
gamma = sac_params["gamma"]
train_freq = sac_params["train freq"]
gradient_steps = sac_params["gradient steps"]
action_noise = sac_params["action noise"]
replay_buffer_class = sac_params["replay buffer class"]
replay_buffer_kwargs = sac_params["replay buffer kwargs"]
optimize_memory_usage = sac_params["optimize memory usage"]
ent_coef = sac_params["ent coef"]
target_update_interval = sac_params["target update interval"]
target_entropy = sac_params["target entropy"]
use_sde = sac_params["use sde"]
sde_sample_freq = sac_params["sde sample freq"]
use_sde_at_warmup = sac_params["use sde at warmup"]
create_eval_env = sac_params["create eval env"]
verbose = sac_params["verbose"]
seed = sac_params["seed"]
device = sac_params["device"]
_init_setup_model = sac_params["init setup model"]
tensorboard_log = sac_params["tensorboard log"]
act_func = sac_params["activation func"]
network_arch = sac_params["network arch"]
# CAN ONLY PASS IN SINGLE ARGUMENT VALUES FOR NETWORK ARCH, NO DICTS
if act_func == "th.nn.ReLU":
policy_kwargs = dict(
activation_fn=th.nn.ReLU, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.LeakyReLU":
policy_kwargs = dict(
activation_fn=th.nn.LeakyReLU,
net_arch=ast.literal_eval(network_arch),
)
elif act_func == "th.nn.Tanh":
policy_kwargs = dict(
activation_fn=th.nn.Tanh, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.ReLU6":
policy_kwargs = dict(
activation_fn=th.nn.ReLU6, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.SELU":
policy_kwargs = dict(
activation_fn=th.nn.SELU, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.ELU":
policy_kwargs = dict(
activation_fn=th.nn.ELU, net_arch=ast.literal_eval(network_arch)
)
else:
policy_kwargs = dict(net_arch=ast.literal_eval(network_arch))
model = SAC(
policy,
env,
gamma=gamma,
learning_rate=learning_rate,
buffer_size=buffer_size,
learning_starts=learning_starts,
train_freq=train_freq,
batch_size=batch_size,
tau=tau,
ent_coef=ent_coef,
target_update_interval=target_update_interval,
gradient_steps=gradient_steps,
target_entropy=target_entropy,
action_noise=ast.literal_eval(action_noise),
verbose=verbose,
tensorboard_log=tensorboard_log,
_init_setup_model=_init_setup_model,
policy_kwargs=policy_kwargs,
seed=ast.literal_eval(seed),
replay_buffer_class=ast.literal_eval(replay_buffer_class),
replay_buffer_kwargs=ast.literal_eval(replay_buffer_kwargs),
optimize_memory_usage=optimize_memory_usage,
use_sde=use_sde,
sde_sample_freq=sde_sample_freq,
use_sde_at_warmup=use_sde_at_warmup,
create_eval_env=create_eval_env,
device=device,
)
print("Custom SAC training in process...")
model.learn(total_timesteps=train_episodes)
if save_model == "true":
# Save the agent
model.save(save_path)
print("Saving the Trained Agent")
log_message = "The trained model was saved"
sio.emit("PyEventMessage", log_message)
elif alg_selected == "SAC":
model = SAC(SacMlpPolicy, env, verbose=1)
print("SAC training in process...")
model.learn(total_timesteps=train_episodes, log_interval=10)
if save_model == "true":
# Save the agent
model.save(save_path)
print("Saving the Trained Agent")
log_message = "The trained model was saved"
sio.emit("PyEventMessage", log_message)
elif (alg_selected == "TD3") and (use_custom_params == "true"):
policy = td3_params["policy"]
learning_rate = td3_params["learning rate"]
buffer_size = td3_params["buffer size"]
learning_starts = td3_params["learning starts"]
batch_size = td3_params["batch size"]
tau = td3_params["tau"]
gamma = td3_params["gamma"]
train_freq = td3_params["train freq"]
gradient_steps = td3_params["gradient steps"]
action_noise = td3_params["action noise"]
replay_buffer_class = td3_params["replay buffer class"]
replay_buffer_kwargs = td3_params["replay buffer kwargs"]
optimize_memory_usage = td3_params["optimize memory usage"]
policy_delay = td3_params["policy delay"]
target_policy_noise = td3_params["target policy noise"]
target_noise_clip = td3_params["target noise clip"]
create_eval_env = td3_params["create eval env"]
verbose = td3_params["verbose"]
seed = td3_params["seed"]
device = td3_params["device"]
_init_setup_model = td3_params["init setup model"]
tensorboard_log = td3_params["tensorboard log"]
act_func = td3_params["activation func"]
network_arch = td3_params["network arch"]
# CAN ONLY PASS IN SINGLE ARGUMENT VALUES FOR NETWORK ARCH, NO DICTS
if act_func == "th.nn.ReLU":
policy_kwargs = dict(
activation_fn=th.nn.ReLU, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.LeakyReLU":
policy_kwargs = dict(
activation_fn=th.nn.LeakyReLU,
net_arch=ast.literal_eval(network_arch),
)
elif act_func == "th.nn.Tanh":
policy_kwargs = dict(
activation_fn=th.nn.Tanh, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.ReLU6":
policy_kwargs = dict(
activation_fn=th.nn.ReLU6, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.SELU":
policy_kwargs = dict(
activation_fn=th.nn.SELU, net_arch=ast.literal_eval(network_arch)
)
elif act_func == "th.nn.ELU":
policy_kwargs = dict(
activation_fn=th.nn.ELU, net_arch=ast.literal_eval(network_arch)
)
else:
policy_kwargs = dict(net_arch=ast.literal_eval(network_arch))
model = TD3(
policy,
env,
gamma=gamma,
learning_rate=learning_rate,
verbose=verbose,
tensorboard_log=tensorboard_log,
_init_setup_model=_init_setup_model,
policy_kwargs=policy_kwargs,
seed=ast.literal_eval(seed),
buffer_size=buffer_size,
tau=tau,
target_noise_clip=target_noise_clip,
policy_delay=policy_delay,
batch_size=batch_size,
train_freq=train_freq,
gradient_steps=gradient_steps,
learning_starts=learning_starts,
action_noise=ast.literal_eval(action_noise),
target_policy_noise=target_policy_noise,
replay_buffer_class=ast.literal_eval(replay_buffer_class),
replay_buffer_kwargs=ast.literal_eval(replay_buffer_kwargs),
optimize_memory_usage=optimize_memory_usage,
create_eval_env=create_eval_env,
device=device,
)
print("Custom TD3 training in process...")
model.learn(total_timesteps=train_episodes)
if save_model == "true":
# Save the agent
model.save(save_path)
print("Saving the Trained Agent")
log_message = "The trained model was saved"
sio.emit("PyEventMessage", log_message)
elif alg_selected == "TD3":
# The noise objects for TD3
n_actions = env.action_space.shape[-1]
action_noise = NormalActionNoise(
mean=np.zeros(n_actions), sigma=0.1 * np.ones(n_actions)
)
model = TD3(Td3MlpPolicy, env, action_noise=action_noise, verbose=1)
print("TD3 training in process...")
model.learn(total_timesteps=train_episodes)
if save_model == "true":
# Save the agent
model.save(save_path)
print("Saving the Trained Agent")
log_message = "The trained model was saved"
sio.emit("PyEventMessage", log_message)
else:
model = {}
log_message = "No learning algorithm selected for training with"
print(log_message)
sio.emit("PyEventMessage", log_message)
sio.disconnect(sid)
log_message = "Training complete"
print(log_message)
sio.emit("PyEventMessage", log_message)
eval_complete = eval_episodes + 2
print(eval_complete)
for step in range(eval_complete):
action, _ = model.predict(obs, deterministic=True)
int_action = action[0]
print("Action: ", int_action)
obs, LocalReward, done, info = env.step(action)
print("obs=", obs, "reward=", LocalReward, "done=", done)
if step == eval_episodes:
print(step)
log_message = "Evaluation Complete"
sio.emit("PyEventMessage", log_message)
sio.disconnect(sid)
# recieves observations and reward from Unreal Engine
@sio.on("BPEventSendObservations")
def sendobs(_, data):
global ObservationFlag
global Observations
global UEReward
global UEDone
ObservationFlag = 1
json_input = json.loads(data)
Observations = json_input["observations"]
UEReward = json_input["reward"]
UEDone = json_input["done"]
# This sets up the server connection, with UE acting as the client in a socketIO relationship, will default to eventlet
if __name__ == "__main__":
if sio.async_mode == "threading":
# deploy with Werkzeug
print("1 ran")
app.run(threaded=True)
elif sio.async_mode == "eventlet":
# deploy with eventlet
import eventlet
import eventlet.wsgi
logging.disable(sys.maxsize)
print("MindMaker running, waiting for Unreal Engine to connect")
eventlet.wsgi.server(eventlet.listen(("", 3000)), app)
elif sio.async_mode == "gevent":
# deploy with gevent
from gevent import pywsgi
try:
websocket = True
print("3 ran")
except ImportError:
websocket = False
if websocket:
print("4 ran")
log = logging.getLogger("werkzeug")
log.disabled = True
app.logger.disabled = True
else:
pywsgi.WSGIServer(("", 3000), app).serve_forever()
print("5 ran")
elif sio.async_mode == "gevent_uwsgi":
print("Start the application through the uwsgi server. Example:")
print(
"uwsgi --http :5000 --gevent 1000 --http-websockets --master "
"--wsgi-file app.py --callable app"
)
else:
print("Unknown async_mode: " + sio.async_mode)
```
11 其他
11.1 连接端口
UE5 与 Python 之间通信的默认端口为 3000 。
在 UE5 中设置端口的方法:
打开 BP_Cart - Components 选项卡 - 选中 Socket IOClient - Details 选项卡 - Socket IO Connection Properties - URLParams - Address and Port: http://localhost:3000
11.2 保存与加载训练好的模型
通过设置 Event Graph 中 LaunchMindMaker 函数的 SaveModelAfterTraining 、LoadModelForContinuousTraining 和 LoadModelForPredictionOnly 参数来确定训练模式:
- 训练后保存模型
- 加载现有模型后继续训练
- 加载现有模型后仅进行预测
注意:在同一时刻,三个变量只能有一个为 True
11.2.1 保存模型
如果需要保存模型,需要在 LaunchMindMaker 函数中将 SaveModelAfterTraining 参数设置为 True 。
训练好的模型以 .zip 格式保存在 C:\Users\<UserName>\AppData\Roaming 目录下。
11.2.2 加载模型
如果要使用训练好的模型,需要在 LaunchMindMaker 函数中将 LoadModelForPredictionOnly 参数设置为 True 。
11.3 使用 TensorBoard 记录训练数据(未测试)
- 将 LaunchMindMaker 函数中的
UseCustomParams参数设置为True - 点击当前使用的 DRL 算法的
XXX Params结构体变量节点 - Details 选项卡 - Default Value - XXX Params - tensorboard log - 填写日志文件夹的绝对路径